
Where Are the Pictures? Linking Photographic Records across Collections Using Fuzzy Logic
Stephen Brown, UK, Simon Coupland, UK, David Croft, UK, Jethro Shell, UK, Alexander von Lünen, UK
Abstract
This paper describes a novel approach to interrogating different online collections to identify potential matches between them, using fuzzy logic-based data-mining algorithms. Potentially, information about objects from one collection could be used to enrich records in another where there are overlaps. But although there is a considerable amount of bibliographic and other kinds of data on the Web that share similar information, a standardized way of structuring such data in a way that makes it easy to identify significant relationships does not yet exist. In the case of historical photographs, the challenge is further exacerbated by the enormous range of subjects depicted, and the fact that surviving records are not always complete, accurate, or consistent and the amount of text available per record is very small. Fuzzy-matching algorithms combined with semantic similarity techniques offer a way of finding potential matches between such items when standard ontology and corpus-based approaches are inadequate, in this case helping researchers for the first time match photographs held in different archives to historical exhibition catalogue records.
Keywords: linked data, semantic, ontology, metadata, fuzzy logic, co-reference
1. Introduction
The volume of online resources has grown exponentially and is forecast to continue to expand similarly into the foreseeable future (Figure 1). This growth creates enormous potential for cross-linkage between records, where there are overlaps, with the possibility of using information about objects from one data set to enrich records in another, thus enhancing their value.
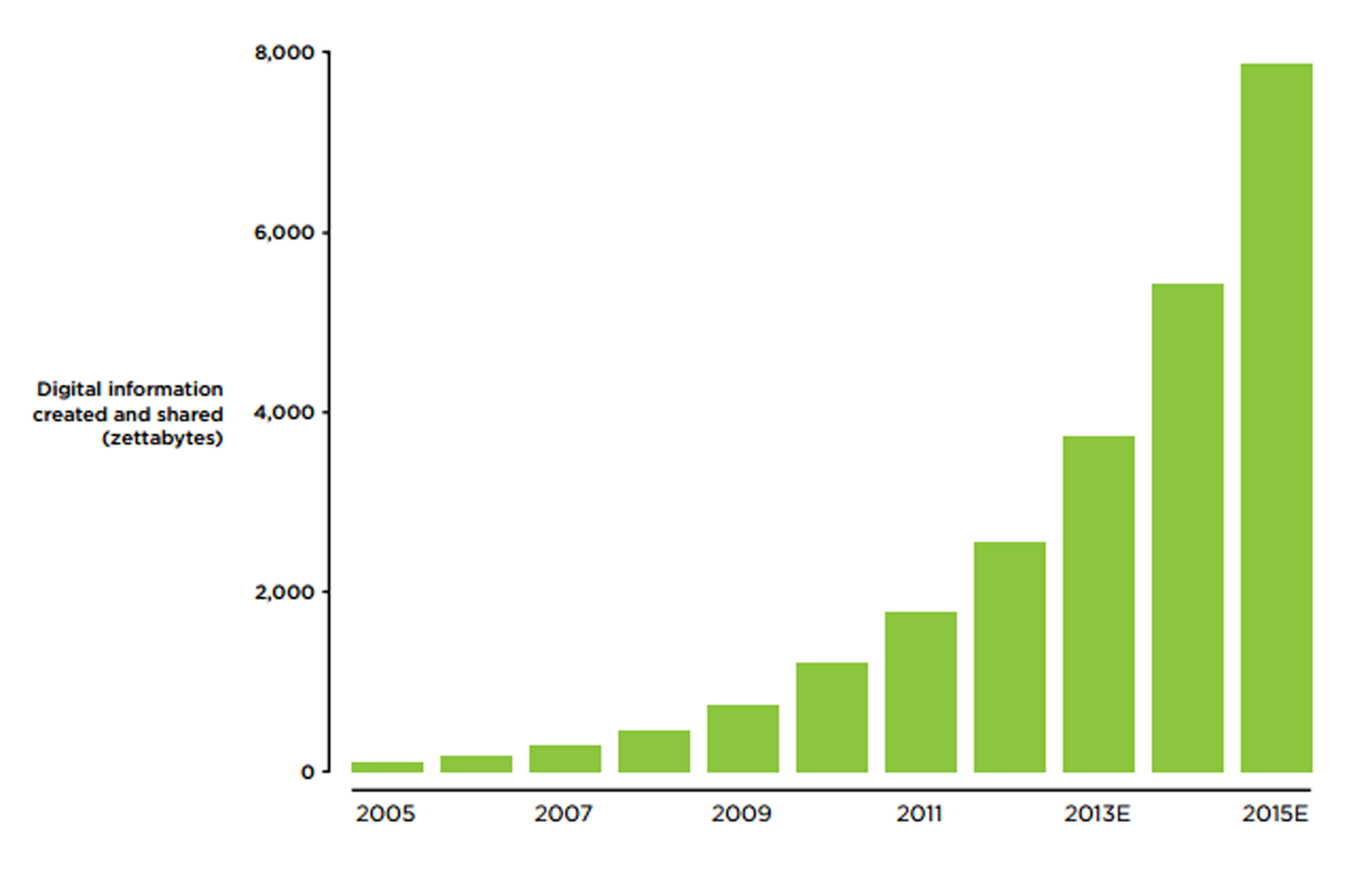
Figure 1: Information availability online from 2005 to 2015 (estimated). Source: IDC VIEW report ‘Extracting value from chaos,’ June 2011 (Fullan & Donnelly, 2013, p. 9). 1 zettabyte = 1 trillion (1018) gigabytes.
Galleries, libraries, archives, and museums (GLAMs) are adding to this content by digitizing their collections. In the United States, an analysis of 18,142 museums and libraries by the Institute of Museums and Library Services (IMLS, 2006) revealed that the majority of museums and larger public libraries make digital records available to the public via the Internet, and the same was true for a smaller proportion of public and smaller academic libraries. Individual institutional postings can run to hundreds of thousands of objects. As of January 2013, the Museum of Modern Art had posted more than 540,000 images, the British Museum offers images of more than 730,000 works, and the Victoria and Albert museum (V&A) website offers access to more than 300,000 images of works in its collection (Kelly, 2013). Collectively, these resources amount to a vast quantity of data. The Europeana aggregator website offers access to 21.3 million objects from thirty-three countries (Europeana, 2012).
However, finding, evaluating, and gaining access to this content is challenging. GLAMs’ object data typically resides in databases, which, while they may have Web-facing search interfaces, are not well integrated with other data sources on the Web. Although considerable amounts of bibliographic and other kinds of data exist on the Web that share information that could be linked, “Without tools and methods for filtering, categorizing, clustering, weighting, and disambiguating our expanding datasets, museums will face increasing difficulty in managing and organizing their online resources, while their visitors will struggle to locate and make use of them” (Klavans et al., 2011). Most of the information in GLAM records is encoded as natural-language text, which is not readily machine processable, and the GLAM and semantic Web communities have different terminology for similar metadata concepts, making implementation of semantic approaches difficult. Considerable interest has been expressed in the concept of linked data (Bizer et al., 2009; Heath & Bizer, 2011; Oommen & Baltussen, 2012), and some progress has been made in the form of REpresentational State Transfer (REST) and RDF Query Language (SPARQL) interfaces (ACRL Research Planning and Review Committee, 2012). But building a data pipeline to convert heterogeneous data from various source collections into common RDF in order to create linked open data that can facilitate searching across multiple collections requires considerable technical expertise (Henry & Brown, 2012). While the onus is on GLAMs to standardize and convert their collections metadata, the prospect of universally linked data remains remote.
This paper describes an alternative approach for helping researchers to find potential matches between such items based on similarity identification, in this case helping researchers to match photographs held in different archives to historical exhibition catalogue records for the first time.
2. Exhibitions of the Royal Photographic Society
From its foundation in 1853, the Photographic Society in London always considered itself as the ‘parent society’ and, after suffering several setbacks during the late 1860s, reemerged to establish itself as the preeminent photographic society of Britain. During the years that followed, the Photographic Society changed its name: first to the Photographic Society of Great Britain in 1874, and then in 1894 to the Royal Photographic Society, the name it retains today.
Although other photographic societies flourished elsewhere in Britain and held their own annual exhibitions, catalogues from these societies have not survived in any significant number. In contrast, the forty-six surviving catalogues from the Photographic Society’s annual exhibitions from 1870 to 1915 contain 34,917 individual exhibit records. Collectively, these exhibition records are a highly significant research resource, offering a unique insight into the evolution of aesthetic trends and photographic technologies; the response of a burgeoning group of photographic manufacturers to business opportunities; and the activities and fortunes of individuals concerned with the technical, artistic, and commercial development of photography. The society’s exhibitions attracted a wide constituency of photographers from Britain, Europe, and America, and many individuals launched their photographic careers by exhibiting at the Royal Photographic Society.
Exhibitions of the Royal Photographic Society 1870–1915 (ERPS; http://erps.dmu.ac.uk) is one of a number of photographic research resources hosted by De Montfort University (http://kmd.dmu.ac.uk/kmd_photohistory_page). These resources have enormous potential to enrich and contextualise records of historical photographs in GLAMs’ collections, if co-referent photographs exist. Equally, matching surviving pictures to the exhibition catalogue records would enhance their value to researchers, particularly since although the ERPS exhibition catalogues contain information about many different aspects of the exhibits, they contain very few reproductions of the photographic exhibits themselves. There are only 1,040 images, most of which are merely artists’ sketches of the originals because, at the time of the exhibitions, mechanical reproduction of photographic images was technically impossible. While many researchers have commended the ERPS database for its usefulness, a common criticism is that most of the pictures are missing. The “FuzzyPhoto” project described here is developing and testing computer-based finding aids aimed at answering the questions:
- Where are the surviving pictures referred to in the exhibition catalogues?
- What do those pictures look like?
3. Research challenges and methods
GLAMs’ collection records generally, and the ERPS records in particular, present a number of challenges. In the case of the ERPS exhibition records, a new exhibition committee each year structured the exhibition into sections that seemed appropriate and labeled exhibits in particular ways. Thus some records have extensive metadata within a large number of fields, while others have only minimal entries under just a few headings. For example, sometimes a complete address is listed for an exhibitor, while for others there is only a neighborhood or a town name. It is unsurprising that address information should change, and equally unsurprising that in some cases exhibitor names changed as well, either through marriage or through promotion. For example, one can trace through the records the career of Lieutenant, later Captain and finally Sir, C.E. Abney. Less expected was that sometimes the same photograph was exhibited in different years by different people and sometimes under a different title.
GLAM records have their own issues. Record management systems and cataloguing conventions tend to vary between institutions, which tends to create structural differences between their respective data sets. Clustering algorithms can be used to identify similarities between different data sets (Dhillon et al., 2003), but when we ran a clustering algorithm on a sample of data from a range of institutions, we found that data clustered most strongly within the originating collections and that clusters of data between collections were very much less evident. In other words, the institutional cataloguing style was so strong that it masked any other similarities that might exist between records in different collections.
The quality of records is also highly variable. In some cases, records are kept as simple spreadsheets, with little or no structure, while other institutions keep meticulous records clearly differentiated into multiple fields. The problem of lack of clear structure is exacerbated when data are entered inconsistently, making it difficult to develop rules for separating out different data elements. For example, examination of the records for one collection revealed that twenty different ways of formatting date information had been used.
In order to compare records across ERPS and GLAMs’ collections, an approach was required that could cope with incompleteness, uncertainty, and inconsistency. The methodology we use comprises four steps:
- Data preparation (correcting typographical errors, standardizing data such as dates, removing duplicate entries and mapping data to a common metadata schema)
- Data aggregation (combining standardized records in a single XML database where they can be mined for similarities)
- Query expansion (extending the range of keywords that are searched for)
- Field comparison (comparing the contents of individual fields and combining these to produce an overall similarity metric)
Figure 2 outlines the overall workflow of the project, showing schematically how collection records are ingested, aggregated, and mined for links that can then be output to partners’ own Web sites, where they can be accessed by visitors to those sites.

Figure 2: Overall project workflow
Data preparation and aggregation
Thus far, the FuzzyPhoto project has acquired circa 1.5 million historical photographic records from GLAMs, including the V&A, British Library, New York Metropolitan Museum of Art, National Media Museum, National Museums Scotland, Birmingham City Library, St Andrews University, the National Archives, the Musée d’Orsay in Paris, and open sources such as Culture Grid. The first step is to convert all the data to a common MySQL table format. CSV files can be imported directly into MySQL, but for XML data, an XML data store (BaseX) and XQuery queries have to be used to convert data to MySQL tables, and an intermediate Microsoft SQL database was necessary to convert British Library (BL) data (Figure 3). After the data are imported, “cleaning up” such as eliminating duplicates or spelling variants is done, chiefly with SQL queries. Some operations, however, are too complex to be handled in SQL, so Java and Python scripts are used externally.

Figure 3: Workflow for mapping different metadata sources to LIDO
The next step is to map the records in the temporary MySQL tables to a common metadata schema. This is necessary because the original collections were catalogued using different schemas, which makes it difficult to compare records between them. We chose the ICOM LIDO metadata schema (http://network.icom.museum/cidoc/working-groups/data-harvesting-and-interchange/what-is-lido/). LIDO is an XML harvesting schema developed for exposing, connecting, and aggregating information about museum objects on the Web. It is ideally suited to the task of standardizing the metadata provided by each of the contributors.
Query expansion
The endpoint of the first stage therefore is a MySQL database of records in LIDO format. The aim is to compare these records in order to identify similarities. Similarity identification, known variously as co-reference identification, record linkage, and entity resolution, is a common problem in many fields, and a correspondingly wide range of approaches have been developed to deal with it (Elmagarmid et al., 2007). Effective techniques have been developed for contexts where there are sufficiently large volumes of text to allow matching of key words (e.g., Luo & Xie, 2009), or where very strong identifiers such as book titles, post codes, or telephone numbers link different items. However, such approaches are of only limited use in the context of GLAMs’ collections, which typically have only limited metadata—often just a title, date and name, and sometimes not even that—and records are not always complete, accurate, or consistent (Tzompanaki, 2012).
In addition to these general problems, most ERPS exhibit titles are just a few words, even though some extend to several lines. The average title length is just 8.1 words, of which only 5.4 are useful, making it very difficult to apply document classification or corpus-linguistics based approaches that rely on matching clusters of similar words in different documents. There are just not enough words in the titles as they stand to find such clusters. Furthermore, the range of subject matter depicted is enormous, including landscapes, events, scientific experiments, medicine, architecture, fashion, museums, folk customs, celebrities, photographic equipment, etc., against which ontology-based matching approaches are ineffective. The requisite ontology would have to cover just about every subject imaginable in the mid- to late nineteenth century.
One way of tackling the problem of limited amounts of text is query expansion. Query expansion uses semantically similar terms to those in a query to increase the chances of locating matching words (Xu & Croft, 1996). Query expansion is relevant in the case of ERPS records because the titles contain so few words and because we know that variants of some photographs appear under similar but not identical titles. By searching for similar words, we increase our chances of finding the same photograph, even though its title may be different.
Before a term can be semantically expanded, its meaning has to be unambiguously defined (Stevenson & Wilks, 2003). Many English-language words have multiple meanings: for example, “fair” can mean “blonde,, “attractive,” “festival,” or “equitable.” Therefore, when matching an exhibit title such as “Fair Daffodils,” the term “fair” has to be disambiguated first. Many semantic disambiguation techniques employ a corpus taken from a specific subject area with text structures that encompass long sentences, or even whole paragraphs, to derive a deep understanding of the context. Since the subject matter of the ERPS exhibits is so diverse, and the exhibit titles are so short, an alternative approach is required. We use the WordNet Lexical database (http://wordnet.princeton.edu/) to identify synsets of keywords, each of which represents a different meaning for that term, and supplementing this with Part-of-Speech Tagging (POST). POST applies descriptors to each element in a sentence (i.e., noun, verb, participle, article, pronoun, preposition, adverb, and conjunction) to help disambiguate the words (Voutilainen, 2003). A comparison of alternative software part-of-speech taggers indicated that the Stanford POST software (http://nlp.stanford.edu/software/tagger.shtml) is the most accurate when used against a test dataset of ERPS records.
Field comparison
Field comparison entails comparing the expanded set of keywords relating to each individual record from the ERPS database (defined as a “seed record”) with the expanded query terms generated for other records in the data warehouse to assess their similarity. Similarity between terms in different records is assessed firstly by comparison between individual fields, and individual field similarity metrics are then combined to produce an overall similarity metric for each pair of records. Overall metrics are then ranked in order of most to least similar.
Thus far, the research has concentrated on just four fields: title, date, creator, and process. Of these, date, creator and process are the most straightforward. The key factor in relation to date is the amount of time between the dates described in the fields. The greater the amount of time between them, the less similar they are. Some of the dates given describe a span of time rather than a specific year (e.g., “1890s,” “the 19th century”). Greater differences between time spans indicate less similarity between fields. For example “19th century” and “1900” are less similar than “1900s” and “1900.”
In the case of the creator field, name comparison is a well-established problem in many areas, and a large number of algorithms exist to compare names which can handle typographical errors, alternative spellings, etc. We use established edit-distance techniques that measure similarity in terms of the number of changes (edits) required to convert one string into another (Winkler, 2006). The technique we use to assess the similarity of process field data matches the stated process with a list of preset keywords describing various known processes. This allows for typographical errors and spelling variations. The various photographic processes are organised into a branched dendrogram structure in which processes sharing specific traits appear on the same branch. Once a field has been matched to a specific locus, it is compared to other fields by finding the shortest path between the processes in the dendrogram. The shorter the distance between the approaches, the more similar they are considered to be.
The title field
The extreme brevity of most ERPS exhibit titles rules out standard statistical text similarity metrics based on analysis of long text strings. Short-text semantic similarity tools such as Latent Semantic Analysis (LSA) and Sentence Similarity (STASIS) overcome this problem, but they are most effective with small volumes of text (O’Shea et al., 2008). As the volume of text increases, the time taken to process it becomes prohibitive. Although the titles of ERPS records are short, there are 35,000, and in total we have 1.5 million records to process. To deal with this volume, we have developed a simplified semantic similarity measure called Lightweight Semantic Similarity (LSS), which significantly lowers the computational overhead without significantly reducing the accuracy of results (Croft et al., 2013). LSS is based on standard statistical similarity metrics known as “cosine similarity” (Manning & Schütze, 1999), but additionally takes into account the semantic similarity between words, with aid of WordNet and POST.
Combined similarity metric
The final step in our workflow is to combine the individual field metrics into an overall record similarity metric. A series of rules was created that describes how to combine and weight the individual metrics. As an expert knowledge approach, it relies on the programmed knowledge of domain experts (Winkler, 2006), in our case derived from a survey of members of the GLAM community to establish the relative importance of the different variables. The result is a series of “if, then” statements (i.e., IF x, THEN y), which represent the rules that a person would use to solve the same task. Rule-based systems are popular for commercial applications, but they often function poorly when faced with imprecise information, where the identity of x may be uncertain. In our case, uncertainty arises from factors such as imprecise dates (e.g., “circa 1890”); lack of definitive information about historical photographic processes, especially since the production of a photograph could entail more than one process; and the potential existence of variants resulting from different prints from the same negative.
The solution to this difficulty is to use a fuzzy rule-based approach. Fuzzy logic allows an object to belong to more than one category, but to various degrees. For example, consider a number of people of different heights. While some are taller than others, the distinction between tall and not tall is not clear cut, and in different contexts a person of average height might be considered both tall and short. Fuzzy logic can accommodate this relativity by assigning a value to such a person that quantifies the extent to which they belong to the group “tall,” giving it greater resilience regarding imprecision compared with crisp logic. Fuzzy logic has been applied previously to resource discovery challenges (Feng, 2012; Lai et al., 2011; Li et al., 2009). However, these approaches were based on analysis of large volumes of text and thus are not applicable in our context. Our approach is tailored to the challenge of comparing records of titles, person names, dates, and processes, in which most fields contain only small amounts of text. The full set of fuzzy rules we use draws on the individual field-similarity metrics to ascertain if the match between a pair of fields is good, and then combines that comparison with other field comparisons as follows:
IF title is good AND person is good, THEN match is good
IF title is good AND (date is good OR process is good), THEN match is ok
IF person is good AND title is bad, THEN match is ok
IF title is bad AND person is bad, THEN match is bad
4. Results
Figure 4 illustrates how the overall similarity values are used to create connections between the records. Starting with a seed record at the root node, the combined rules identify the record with the highest similarity to that seed record and adds it as a child node. The record with the highest similarity to either of those two nodes is then added, creating a branching tree-like structure, and so on until all the records are added to the tree and the process ends. The connections shown in Figure 4 are just the topmost level of the complete dendrogram.
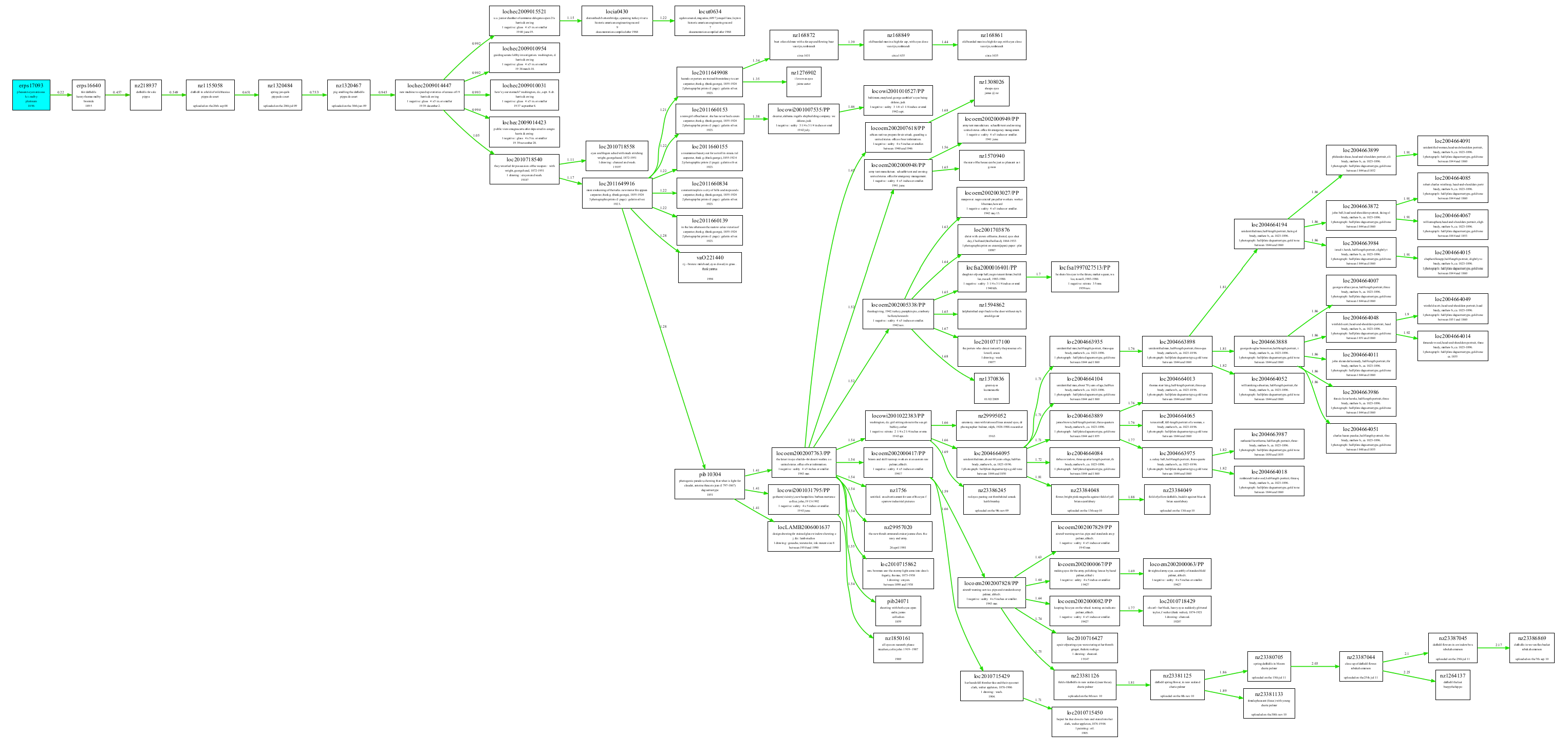
Figure 4: Top-level dendrogram of search results for a single ERPS seed record
The result is that those records with the greatest similarity to the seed record appear in the highest layers of the tree. Of course, a similar effect could be achieved by simply selecting the records with the highest similarity to the seed record. However, this approach does more than just select the records with the greatest similarity to the seed record; it also groups similar records together within the hierarchy. For example, records with the same/similar person fields will be grouped together, which allows for easy exploration of all the records by a single photographer.
Figure 5 shows the results of one such search relating to ERPS record erps28409, a portrait of George Meredith, exhibited by Fred Hollyer in 1909. Examining the metadata for the records, it appears that erps28409 was not the original study. In fact, V&A exhibit vaO75248 was created first by Frederick Hollyer in 1886, then later erps28409 was created for exhibition in 1909 by enlarging of a portion of vaO75248. An etching was also produced by Frederick’s brother Samuel in 1900, which resulted in the Library of Congress record loc92512466.

Figure 5: Comparison of results of search for seed record erps28409
What is remarkable about these results is that while the images are patently similar, from a computational perspective the metadata for each is quite different. For example, as human beings we can see that the creator names “Fred. Hollyer,” “Hollyer, Samuel,” and “Hollyer, Frederick” are similar, but as they are not identical in the way they have been expressed, a simple word-by-word comparison would not work. However, it should be noted that these are preliminary results, and confirmation of the efficacy of the proposed approach must await full-scale implementation. Thus far, we have tested a sample of the outcomes on a panel of subject experts, to compare speed and accuracy of co-reference identification between expert human beings and our computer algorithms. The results indicate our new approach is at least as accurate as techniques employed by experienced researchers, historians, and curators, and considerably faster if the offline processing time needed to create the links database is discounted.
5. Conclusions
Cultural heritage institutions are beginning to explore the added value of sharing and connecting data. Recent moves towards making GLAMs’ records available in computer readable formats such as XML and JSON and making the collections searchable using REST and SPARQL interfaces go some way towards improving access to collections records, but a major barrier to effective sharing across multiple platforms is the absence of machine-readable text standards that make it easy to automate the process of identifying significant relationships between records. Most of the information in GLAM records is encoded as human-readable text, which is not readily machine-processable, and GLAM semantic Web communities have different terminologies for similar metadata concepts, making implementation of semantic approaches difficult. While linked open data offers a tantalizing glimpse of what the future could contain, the reality is that universally applied and adopted standards are a remote possibility for the foreseeable future. Alternative approaches are needed that can work with the messy characteristics of existing collection records.
This research shows that low-cost, lightweight approaches to co-reference identification may be possible, although further work is required to prove the results beyond a pilot study so far, and refinements would be needed to reduce processing time and extend the approach to other domains. A further problem is variation in the structure and quality of GLAM records. Each contributing institution has its own records management system and distinctive cataloguing style. This has necessitated manual data cleansing and mapping to an appropriate common metadata schema. In order to open this approach more widely to other institutions, ways need to be found to automate these labour-intensive data preparation stages.
Acknowledgements
This research is funded by the UK Arts and Humanities Research Council AHRC Research Grant AH/J004367/1. Thanks are due to Birmingham City Library, the British Library, the Louvre, the Metropolitan Museum of Art, Musée d’Orsay, the National Archives, the National Media Museum, National Museums Scotland, St Andrews University, the V&A, and Professor Roger Taylor for their generous support.
References
ACRL Research Planning and Review Committee. (2012). “2012 top ten trends in academic libraries.” College & Research Libraries News 73 (6), 311–320. Consulted October 28, 2013. http://crln.acrl.org/content/73/6/311.full.pdf+html
Bizer, C., T. Heath, & T. Berners-Lee, T. (2009). “Linked data – The story so far.” International Journal on Semantic Web and Information Systems 5 (3), 1-22.
Croft, D., S. Coupland, J. Shell, & S. Brown. (2013) “A fast and efficient semantic short text similarity metric.” In Y. Jin and S. A. Thomas (eds.), Proceedings of the 2013 UK Workshop on Computational Intelligence (UKCI 2013). Surrey: University of Surrey. (In press.)
Dhillon, I., J. Kogan, & C. Nicholas. (2003). “Feature selection and document clustering.” In M. Berry (ed.), A Comprehensive Survey of Text Mining. Berlin/Heidelberg: Springer-Verlag, 73-100.
Elmagarmid, A., P. Ipeirotis, & V. Verykios. (2007). “Duplicate record detection: A survey.” IEEE Transactions on Knowledge and Data Engineering 19 (1), 1–16.
Europeana. (2012). Breaking new ground: Europeana annual report and accounts 2011. The Hague: Europeana Foundation. Consulted October 28, 2013. http://pro.europeana.eu/documents/858566/ade92d1f-e15e-4906-97db-16216f82c8a6
Feng, J. (2012). “Efficient fuzzy type-ahead search in XML data.” IEEE Transactions on Knowledge and Data Engineering 24 (5), 882-895.
Fullan, M., & K. Donnelly. (2013). Alive in the swamp: Assessing digital innovations in education. London: Nesta. Consulted September 5, 2013. http://www.nesta.org.uk/areas_of_work/public_services_lab/digital_education/assets/features/alive_in_the_swamp_assessing_digital_innovations_in_education
Heath, T., & C. Bizer. (2011). “Linked data: Evolving the Web into a global data space.” Synthesis Lectures on the Semantic Web: Theory and Technology 1 (1), 1–136.
Henry, D., & E. Brown, E. (2012). “Using an RDF data pipeline to implement cross-collection search.” In D. Bearman and J. Trant (eds.). Museums and the Web 2011: Proceedings. Toronto: Archives & Museum Informatics, 2011. Last updated March 25, 2012. Consulted September 5, 2013. http://www.museumsandtheweb.com/mw2012/papers/using_an_rdf_data_pipeline_to_implement_cross_.html
IMLS (2006). State of technology and digitization in the nation’s museums and libraries. Washington, DC: The Institute of Museums and Library Services. Consulted October 25, 2013. http://web.archive.org/web/20060926090433/http://www.imls.gov/resources/TechDig05/Technology%2BDigitization.pdf
Kelly, K. (2013). Images of works of art in museum collections: The experience of open access – A study of 11 museums. Washington, DC: The Council on Library and Information Resources. Consulted October 28, 2013. http://www.clir.org/pubs/reports/pub157/pub157.pdf
Klavans, J., R. Stein, S. Chun, & R. D. Guerra. (2011). “Computational linguistics in museums: Applications for cultural datasets.” In J. Trant and D. Bearman (eds.), Museums and the Web 2011: Proceedings. Toronto: Archives & Museum Informatics, 2011. Last updated March 27 2011. Consulted September 5, 2013. http://conference.archimuse.com/mw2011/papers/computational_linguistics_in_museums
Lai, L. F., C. C. Wu, P. Y. Lin, & L. T. Huang. (2011). “Developing a fuzzy search engine based on fuzzy ontology and semantic search.” In Proceedings of IEEE International Conference on Fuzzy Systems. Taipei: IEEE, 2684-2689.
Li, F. Z., D. Y. Luo, & D. Xie. (2009). “Fuzzy search on non-numeric attributes of keyboard query over relational databases.” In Proceedings of ICCSE ’09. 4th International Conference on Computer Science and Education. Nanning, China: IEEE, 811-814.
Manning, C. D., & H. Schütze. (1999). Foundations of statistical natural language processing. Cambridge, MA: MIT Press.
Oommen, J., L. Baltussen, & M. van Erp. (2012). “Sharing cultural heritage the linked open data way: Why you should sign up.” In J. Trant and D. Bearman (eds.), Museums and the Web 2011: Proceedings. Toronto: Archives & Museum Informatics, 2012. Last updated March 25, 2012. Consulted September 5, 2013. http://www.museumsandtheweb.com/mw2012/papers/sharing_cultural_heritage_the_linked_open_data
O’Shea, J., Z. Bandar, K. Crockett, & D. Mclean. (2008). “A comparative study of two short text semantic similarity measures.” Lecture Notes in Computer Science, 4953, 172-181.
Stevenson, M., & Y. Wilks. (2003). “Word sense disambiguation.” In R. Mitkov (ed.), The Oxford Handbook of Computational Linguistics. Oxford: Oxford University Press, 249-265.
Tzompanaki, K. (2012). “A new framework for querying semantic networks.” In J. Trant and D. Bearman (eds.), Museums and the Web 2011: Proceedings. Toronto: Archives & Museum Informatics, 2012. Last updated March 25, 2012. Consulted September 5, 2013. http://www.museumsandtheweb.com/mw2012/papers/a_new_framework_for_querying_semantic_networks
Voutilainen, A. (2003). “Part-of-speech tagging.” In R. Mitkov (ed.), The Oxford Handbook of Computational Linguistics. Oxford: Oxford University Press, 219-232.
Winkler, W. E. (2006). “Overview of record linkage and current research directions.” Research Report Series (Statistics #2006-). Washington, DC: U.S. Census Bureau. Consulted October 28, 2013. http://www.census.gov/srd/papers/pdf/rrs2006-02.pdf
Xu, J., & W.B. Croft. (1996). “Query expansion using local and global document analysis.” In H.P. Frei, D. Harman, P. Schaubie, and R. Wilkinson (eds.), Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 4-11.
Cite as:
S. Brown, S. Coupland, D. Croft, J. Shell and A. von Lünen, Where Are the Pictures? Linking Photographic Records across Collections Using Fuzzy Logic. In , N. Proctor & R. Cherry (eds). Silver Spring, MD: Museums and the Web. Published September 9, 2013. Consulted .
https://mwa2013.museumsandtheweb.com/paper/where-are-the-pictures-linking-photographic-records-across-collections-using-fuzzy-logic-2/